Dan Bricklin's Web Site: www.bricklin.com
|
|
Rethinking Forms in the Age of Tablets and Amazon S3
The capabilities of tablets and the availability of huge, inexpensive, quickly accessed data stores, help us break out of the shackles of paper forms which are the legacy of punched cards.
|
|
Introduction
In a TV commercial AT&T is currently running, titled "Baker's Delight," a small businessman questions an AT&T salesman: "...My drivers don't have time to fill out forms." The salesman replies: "Tablets. Keep them all digital." This exchange struck me as quite strange. How does "keeping it digital" save time for the driver? I can understand how it saves time for the data entry person who used to key in the paper forms back in the office, but isn't simply moving a paper form to a tablet, with its cumbersome keyboard and visible screen area smaller than the paper it is replacing, not much of an improvement? And, anyway, isn't the AT&T salesperson ignoring the need to create software that would be better than the paper without which the tablet is just a paperweight or video viewer?
I know from the many users of my NoteTakerHD iPad app that taking existing blank paper forms (as PDF files) and filling them out on a tablet, using either digital ink (handwriting kept as strokes) or overlaid typed-in text, is very popular. There are advantages over paper in organization, weight, and transmission to the customer or home office. However, it seems like a lateral move, trying to do what older systems did in a new medium without addressing the underlying needs that the old system was addressing or the strengths and weakness of both. I'm reminded of filming a play with a camera fixed in one position in the audience -- that mimicking of one medium in another is one type of "movie" but not where film evolved and extended the ability to do storytelling and more.
Many people have told me how the tablet gives them advances over paper when they can take photographs and then draw annotations on those photographs. This means they are starting to break out of just copying the old paper forms and instead rethinking what is needed.
At Alpha Software I have been working as CTO exploring the ways in which mobile devices, including tablets like the iPad, can help businesses improve their internal processes. Rather than concentrate on consumer use, a major driver of tablet software design at Apple and elsewhere, I have been looking at the needs of businesses.
What I want to cover here is the area that has been served by paper forms. They are just one example of a means for addressing the needs of an organization, and, I believe, a means this is not always as good as what came before or as what we can now efficiently do after.
What need does a form serve?
Let me define some terms as I'll use them here. When I refer to a "paper form," I mean something like those filled out when inspecting a house or piece of equipment, when doing healthcare or in the process of practicing medicine, or keeping track of the manufacturing history of a part for an aircraft. These are types of manual data collection and recording. The traditional image is of a person with a clipboard, pre-printed forms, and a pen. For simplicity, I'm not going to address more transactional types of forms, such as for submitting an order.
The activity is a person interacting with the environment around them, and capturing information to be used in the future. There are other means for capturing information mechanically (such as that addressed by sensors and the Internet of Things) but in this case we are mainly looking at a person participating in the process using a combination of their senses, their knowledge, and their reasoning.
Let's think about the capture of information this way.
Data Capture is Not New
Data capture for later use is not something new as a human activity. Organizations have been doing it for thousands of years. Looking at some of those old (pre-computer) examples can be helpful for understanding the generic needs and for developing a taxonomy of data capture.
Some very old recorded examples of data capture can be found in a document that has been well known to many in Western civilization for thousands of years: The Bible. In a book even named for the activity, the Book of Numbers (referring to the taking of a census), there is a well-known example I'd like to highlight.
(The biblical translation I use comes from "The Five Books of Moses" translation by Everett Fox. It is a translation that is close to the original Hebrew in rhythm, nuance, and stylistic devices.)
In Numbers, Chapter 13, verses 17-20, it is written:
"Now when Moshe [Moses] sent them to scout out the land of Canaan, he said to them: Go up this (way) though the Negev/Parched-Land, and (then) you are to go up into the hill-country.
And see the land -- what it is (like), and the population that is settled in it: are they strong or weak, are they few or many;
And what the land is (like), where they are settled: is it good or ill; and what the towns are (like), where they are settled therein: are (they) encampments or fortified-places;
And what the land is (like): is it fat or lean, are there in it trees, or not? Now exert yourselves, and take (some) of the fruit of the land -- now these days (are) the days of the first ripe-grapes.
Among other things, what I see here are: Instructions about where to go about finding the data (parched-land then hill country), what specific data to make sure is captured, and how to measure that data. This includes three sections of information: About the people, the population centers, and the land itself. It lists specific choices and measurements to use (which read like a modern checklist), as well as requesting visual examples needed for detailed examination and "auditing" later. (With no photographs or drawings possible in those days, a sample of a type of fruit known to all and known to be available was specified as being required even if it was hard to obtain and transport.) While general, open-ended, narrative reporting was also used, the instructions made sure that the required data is included. Also, multiple people were involved in the data collection. The type of activity, unlike many others described in that part of the Bible (such as walking through a parted sea or food in the desert), as I've heard it, has never been described as being out of the ordinary. Collecting data like this was a normal part of an organization's activity even back then and ever since.
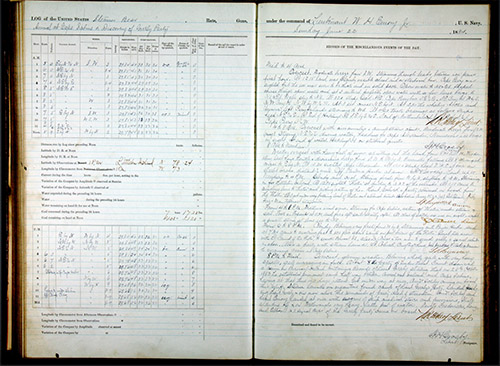
Moving closer to modern times, in the nautical world logbooks have been kept for centuries. These include day by day or even hour by hour recording of speeds, temperature and other meteorological readings, as well as incident descriptions and drawings, as well as logs for lighthouses and information about commerce. What we know of many explorers, such as Magellan, comes from these logbooks. Archivists around the world have these records. (See the USA's Vessel and Station Log Books at the National Archives, the UK's Historical Meteorological Recordings from the UK Colonial Registers and Royal Navy Logbooks (CORRAL), and The Mariners' Museum's Logbooks.)
Here are some images from the National Oceanic and Atmospheric Administration from the logbook of the US Navy steamer Bear, June 22, 1884:
    There are numerous examples of data captured about wildlife, such as by Charles Darwin and John James Audubon. Darwin kept logbooks about landforms, mountains, rocks, and soil, as well as information about the wildlife he encountered. Audubon is known for his drawings of birds, but also worked with physical specimens (from which he drew) and written notes of bird behavior (which probably helped him pose his dead specimens). Before the days of audio recording, observers learned to use mnemonics to express the sounds heard. (Examples are "Sweet, sweet, I'm so sweet" for a yellow warbler, "Oh sweet Canada" for a white-throated sparrow, and "Who cooks for you?" for a barred owl.) Musical notation has been using to transcribe bird sounds for at least a few hundred years. Other written methods were tried before mechanical sound recording was possible. (See this page and the article it's in.)
One thing we see in so many of these examples is the wide range of types of data captured, and the need to tailor things to the specific task.
Handwriting for data recording had the property of being able to express a wide range of these types of data. For example, you could write any text or numbers, you could sketch illustrations, diagrams or graphs, you could use musical and other notations, etc. The ongoing nature of data capture by each individual in a log book lent itself to having space for varying-size data entries -- you could just continue writing down the page or continue on the next, or you could write smaller to fit more in a fixed grid space. The nature of the data could be explicit, or inferred from the context.
Computerization
Starting in the late 1880's, the precursors to today's computers were used to capture and process the data captured in the United States Census. Herman Hollerith's punched cards have a direct line to today's data processing and use of forms.
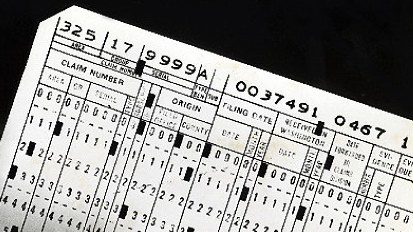
Those early paper cards had 24 columns of 12 row positions for holes. Each hole or group of holes could be used to represent a piece of data, such as married vs. single. Later cards had, most commonly, 80 columns with 12 rows each. Those 80 columns with 0 to 6 of the row holes punched through were most commonly used to represent 80 characters (letters, numbers, and some punctuation) of data. Data was entered by using a special machine with a keyboard to punch the holes. Cards were sorted and filtered using machines which could detect the holes and direct the cards to different bins. The cards with data could be processed to get totals and printouts using other machines. The data was in "known" fixed locations on the cards. For example, a sequence number may be assumed to be in columns 73-80, or a customer ID in columns 5-30.
An entire "business machine" industry was built up around this means for entering and storing data. (The company Hollerith founded eventually became International Business Machines -- later called just IBM.) Even as screen-based computers entered, for decades the 80-character column format, with those characters chosen from a main set of up to 128 symbols, endured.
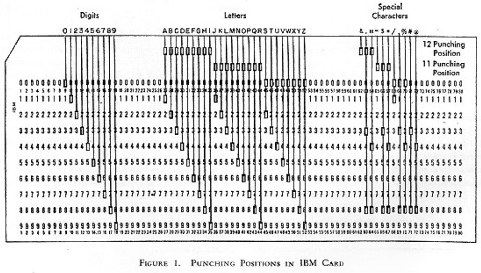  Two images of punched cards from the Computer History Museum Punched Cards exhibition
 Photo I took at the Computer History Museum of an IBM 029 Card Punch like the ones I used in the 1960's
Computer data storage and processing costs drove the decisions on what types of data could be used. Initially, short identifiers and numbers dominated, with fixed length fields to simplify processing. General use for long strings of text, like paragraphs and long narratives, was prohibitive. Even the extra two characters of a year (1967 vs. just 67) were usually deemed not worth storing (leading to the Y2K situation). Over time, text was acceptable but image data was prohibitive, then images became acceptable but the larger audio data was prohibitive, etc.
You can see how the common paper form fit into this system. It was designed for simple text, fixed sized fields, filled out with a typewriter or careful hand printing. The data in the forms was then keyed in to a computer system.
There are advantages to using paper forms for initial data capture and later entry rather than directly entering into a computer. Paper forms are portable. They can be used by people who perform their jobs walking around or standing up. This is very often the situation where data collection is done. Directly typing into a desktop (or later a laptop) computer does not fit these situations. A clipboard, some paper forms, and a pen are relatively inexpensive and light. They are easily provided by an organization to the people who need them.
The forms themselves had to fit on common paper, such as 8 1/2"x11" in the USA. These could be handled by normal business systems, such as file drawers, 3-ring binders, fax and copy machines, etc. Fitting everything on one page, or as few pages as possible, was often helpful and sometimes a goal. Sometimes guidance material explaining how to obtain a piece of data or how to evaluate what is being observed was included, taking up space on the form and increasing the page count. Minimizing the "white space" on a form and increasing the information density often seemed to be a goal. Paper is a fixed medium and if particular fields of data are not always used on a form, they still take up space. Navigation through a form can be difficult and error-prone if a user is not familiar with it. The balance between ease of data entry, speed of data entry, data integrity, speed of keying the filled-in form into a computer, and other factors, can be difficult. Validating the data upon entry (such as checking for appropriate values, non-conflicting choices, etc.) is difficult.
Even as computers became better able to handle a wider range of data types, the need to capture on paper and then transcribe using a keyboard, and process with text-oriented systems, kept the data types constrained. The keyboards started by having both text sections as well as dedicated numeric keypads for numeric data entry. (For entering large amounts of numeric data a skilled operator can be much faster with a keypad, especially when moving one hand down the source material while keying with the other.) Keyboards tailored to other types of input, for example with extra keys to represent common values, were only justified in certain high-value or high-volume situations. Data that does not fit into this format (i.e., not fields of text) needs to be kept separate, often in a different storage system, including physical storage.
The creation of the paper forms in the last few decades has mainly been accomplished using systems like word processors and spreadsheets with facilities for drawing borders, rules, and other lines. Sometimes, dedicated graphic artists are used.
Even though a lot of data captured on paper forms is never entered into a computer, and may just be saved in a file drawer "just in case it's needed", many forms fit into this "computer-ready" mold. That's just what forms were in people's minds.
The Nature of Forms
We can deduce many things about forms and data collection.
Each data collection task or situation has its own group of data items to be collected. Unlike something like a simple purchase order or receipt, where a single generic form can serve a large percentage of needs, a data collection form is very likely to require specific customization and not be generic. In addition to the choice of items, the descriptions of what is being captured, the data types, and the range of values that would be acceptable, must be tailored to the task, the particular sources of the data, the nature of the people who will enter the data on the form, and the needs of those who will use that data. That is why there are so many different forms, even for what seem like similar tasks.
Data capture has a big mixture of repetition and customization. There are homogeneous items, such as value readings from many gauges in a plant, or the state of many valves, and homogeneous input data field formats, such as short text fields, numeric fields, or checkboxes. There are heterogeneous items, such as temperature readings, valve states, descriptions of corrosion condition, and inspector signatures all on one form, and heterogeneous input data fields, such as choice lists of different choices and number of choices, or signature fields vs. a place for an illustration or diagram.
For best usability, constructing a particular form out of the homogeneous and heterogeneous pieces that make it up must be done with understanding. A poorly designed form may not accept the full range of data that must be entered, or may be cumbersome, time-consuming, and error-prone to use.
In paper forms, the physical constraints of sheets of paper add additional challenges to the design of the layout. Evolving a form as needs change can be challenging when you are modifying many tightly constructed layouts.
Given all of the above, it's clear why creating forms is so much a manual task.
Paper forms, as I've portrayed them here, are clearly not an optimal solution for all data collection. In addition to the layout challenges, data entry is done with one-size-fits-all keyboards and character sets, and image and other data does not fit into that workflow. Space for "just in time" instructional material is limited and the medium for that material is restricted to what can be printed. Input has to be expressly entered, sometimes having the person perform operations outside of the form, such as translating values or transcribing from a different medium. The entry of data does not easily impact the presentation of what else must be entered based on those values.
Today's Computer Capabilities
There are two additions to the world of "normal" computing (i.e., common and reasonably priced) that I feel will break this hold paper forms have had on manual data collection. They are the tablet, such as the Apple iPad, and the availability of huge, inexpensive, quickly accessed data stores, such as Amazon S3 and various NoSQL systems.
The tablet is large enough to display both many fields of data for navigation during entry, as well as space for touch entry controls and explanatory material. The tablet has the ability to use a camera and microphone for functionality such as capturing still images, video, and audio, and for reading barcodes and other visual recognition tasks that speed input and cut down on errors. It can have GPS capabilities as well as accelerometers. It can have Wifi as well as cellular communications capabilities. The multi-touch display enables the creation of custom controls to act as keyboards and keypads, sliders, spinners, and more, and the ability to draw with one's finger or a stylus or the dragging of objects into position. It has a color display, and a graphics processor that can easily render animations, scroll, zoom and pan, and display full-motion video at high resolution. Tablets come in a variety of sizes, and can be quite light, on par with a clipboard and paper, are available at manageable price points for an enterprise.
Tablets, if programmed for it, can easily combine or juxtapose old and new data. This can make it easier to inspect prior data when needed. Photos and diagrams can be used as backgrounds for positioning measurements, written or typed annotations, and even voice annotations. Multiple annotations can be collected over time on the same sheet or image. Data can be validated as it is entered, with instructional material available to be tailored to the data and presented in many forms, including video.
So, the tablet can handle all of the data types traditionally handled by paper forms, but can also handle a wide variety of valuable additional data types and better display the other material on a form. They are not restricted to fixed layouts, and can tailor the display to the data as it is entered.
For this purpose, tablets are a major step up from desktop and laptop computers. Desktop keyboards basically entered the same types of data that keypunch operators did. A desktop mouse opened up a little bit more, with easier use of checkboxes and a few other controls. A trackpad added little to that. Most laptops had no connectivity in the field. But a handheld, multi-touch tablet is like magic in comparison. Photos, drawing, talking, and GPS, the possibility of connectivity in the field and use while standing up -- these are finally superior in many respects to even a paper logbook in the hands of an able artist in addition to being better than paper or traditional computer data capture and entry.
The old world of pure handwritten data capture was rich and holistic, but the switch to paper forms gave us a limited, constrained view of the real world that we are measuring. The capabilities of tablets help us break out of the shackles of the legacy of punched cards.
The traditional data storage used in organizations, typified by Oracle, SQLServer, and MySQL databases, were designed around record and field oriented data organization. For storing names, addresses, quantities, and part numbers, this was fine. But they were less suited for large, varying sized pieces of data, such as photographs, audio, video, new data types like digital ink, etc., as well as less-structured data such as that expressed in JSON, XML, and object forms. The older systems were hard to scale up and down as needed, leading to expensive capacity bought "just in case" or for anticipated spikes, or to running out of storage space.
The newer systems, typified by cloud services like Amazon S3 storage and NoSQL systems implemented on AWS and other cloud providers or in-house, make it much more practical to capture, store, process, and retrieve non-text-record data, such as image and video. Even the older systems can make some use of such data by storing short unique identifiers to data stored in these high-capacity, low-cost systems.
Creating the New Forms Applications for Tablets
The next part of this essay is about the systems that will be necessary for creating the data capturing software to run on tablets.
Just taking an image of a paper form and putting it on a tablet screen is not the answer. It sounds good: "Using the same form will not be disruptive to current users", "we need to output exactly what's on the current form anyway". However, when you examine the details, you find problems.
First of all, just using the current form would be the same restricted set of data. Second, the tablet screens are usually smaller than the printed area on a paper form. The positioning accuracy of a finger on a touch display is much coarser than a mouse or arrow keys, or a fine pen or pencil, so navigating requires zooming, panning, and scrolling to use the same form. Tablet on-screen keyboards obscure much of the screen, and can obscure fixed position input fields. Tablet keyboards are usually cumbersome for mixed alphabetic and numeric data so common in data entry but less common in personal communications, like email and messaging.
In short, just recreating the same exact form on the screen (as many of my NoteTakerHD users were doing when they marked up existing PDF templates) gives you a few of the advantages of a tablet, but many of the weaknesses of the paper form along with the weaknesses of the tablet. It can be the worst of both worlds. What you need to do is build new applications that are tailored to the capabilities of the tablets and the needs of the task.
If you are going to build new applications for data capture on a tablet, and not just position typing areas over a paper form image, what should the system be like?
I think that such a system must be able to create what I'll call Tablet-Optimized Forms. These are applications that run on the tablet that can take advantage of a wide range of input types, that can have input means that are tailored to the needs of the particular data type and data values being entered, that can have layouts that are flexible, and that are customizable to the needs of the particular task. These Tablet-Optimized Forms must be able to be built relatively inexpensively and quickly, hopefully by people involved in the part of the organization that uses them. Unlike traditional marketing-oriented B2C mobile apps, $50,000-$1,500,000 development costs, and long development cycles, are out of the question.
Custom vs. Repetition
There is an example of a move from paper to computer that I think is instructive here. That is the move from paper to electronic spreadsheets. (An area I have a lot of experience with...)
The spreadsheet was designed for working with a combination of text and numbers. The text was to be used for both data (such as the name of a payee in a list of transactions) as well as for labeling adjacent individual cells, rows, or columns. The numbers usually represented values of some sort, such as time (year or month or day), quantity, or currency. Often, the numeric values (and sometimes, text) needed to be the result of a calculation based on other values, such a totals or projected values.
An important part of a spreadsheet (and improvements in later spreadsheets after the first helped ensure their popularity) was in the formatting of the values. For example, displaying currency in the USA as dollars and cents, left or right justifying text and numbers as appropriate for the position on the display, differing fonts, and appropriate use of cell borders.
When doing financial forecasting, or listing values on a spreadsheet and doing calculations on those values, there is a lot of repetition. A column of computed values may all have similar formulas and formatting. On the other hand, any specific cell may have a custom formula and/or display format.
What the electronic spreadsheet did, starting with VisiCalc, was make it easy to take advantage of repetition, such as copying a formula repeatedly with just a few keystrokes (or later a single mouse drag) while automatically handling the minor changes needed for each cell. (This was done through the use of "relative" and "absolute" cell references.) As I quoted David Reed in a post about VisiCalc, "it allows for regularity, while not requiring it (any individual formula in the repetitive structure could be overridden as a special case)."
This made the spreadsheet a very powerful tool: The ease of replication with automatic customization, coupled with the ease of specific local customization of formula, format, and location.
For developing Tablet-Optimized Forms, a development system needs to meet a similar need of easy repeating of field attributes, along with easy customization of the visual presentation and layout, and the type of input controls. If a development system requires you to "hand code" each field and input control, then it will be too labor intensive to use. If it doesn't allow for customization, then it probably won't be able to handle a wide enough range of situations, and be more of a special-purpose, lightweight demonstration than an industrial-strength tool.
Alpha Anywhere's Approach
The company I work for, Alpha Software, produces a development system called Alpha Anywhere. Alpha Anywhere is a front-end and back-end, low-code, rapid mobile application development and deployment environment. (Low-code is a term meaning that it provides a visual, non-line-by-line-code interface for specifying an application (e.g., dialog boxes, tree controls, drag-positioning, etc.) with programmer-friendly facilities for integrating custom code written in common, familiar computer languages, like JavaScript, CSS, SQL, and Basic.) The mobile applications themselves are created in HTML, CSS, and JavaScript, with optional use of PhoneGap for the construction of installable hybrid apps that have access to native functionality.
We are enhancing Alpha Anywhere with new features for better developing Tablet-Optimized Forms. We have released an early beta version of these features. Seeing what we are doing can be instructive in figuring out how we can best make use of tablets for this purpose.
Here are some screenshots of a sample application built using these features:
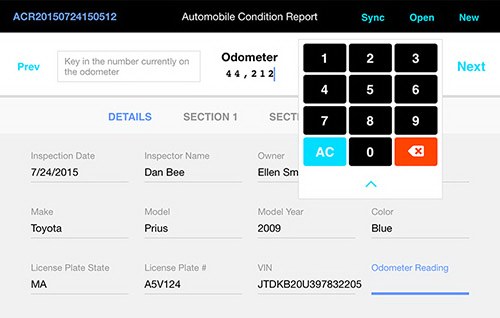 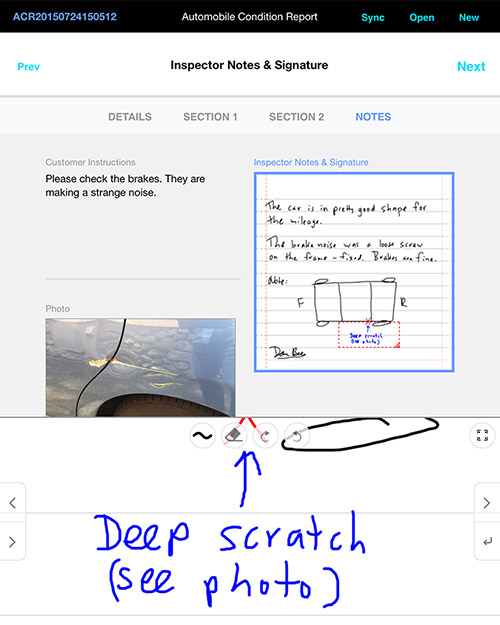 Here is a video demonstrating the sample application:
What you see in the sample is the use of custom "editors" for data entry. Those editors are tuned to the type of data and the particular value being entered. (For example, numeric keypads for phone numbers and mileage with slightly different displays of the values, and a special alphabetic and numeric keypad for license plate "numbers" and vehicle identification.) You also see the capture of image data (a photograph) as well as handwriting and drawing.
One of the specific features added to Alpha Anywhere is called the FormView control. This control displays the fields on the form, and coordinates the display of the custom editors as well as integration with the main local storage of the field data. It is driven by JSON data, including a powerful templating language for creating the visual display of the form, leveraging HTML and CSS.
While being architected this way gives the developer great flexibility in creating a form, creating a full form description for a complex form with many fields in HTML and JSON can be tedious and error-prone. To avoid this, Alpha Anywhere includes an automatic builder for creating and modifying a FormView definition. This lets the developer, using the schema of the data being entered and displayed, specify the contents of the form, how the fields are displayed, and how they behave and are connected to custom editors. This is done using developer-friendly dialogs, simple lists and trees, and property sheets. The builder then automatically builds the code. This builder-level construction makes repetition easy, but it is coupled with easy customizations to apply to those repetitions in both the input means and display means.
For example, here are some screenshots from the beta version of the full-power builder (simpler ones are in the works):
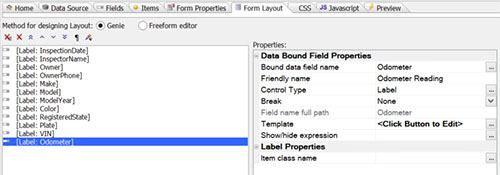 Form Layout tab showing list of fields to display along with attributes for display and behavior
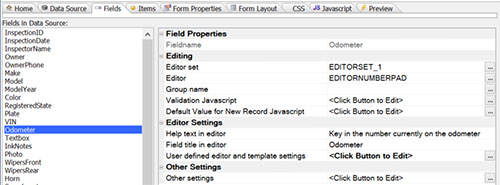 Fields tab showing editor information for the field with user defined editor and template settings
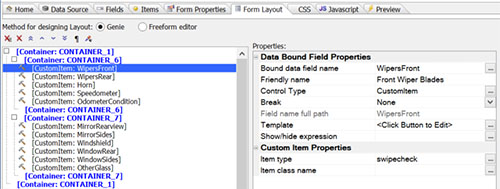 Form Layout tab of another form, showing tree on left of visual items and custom control item type
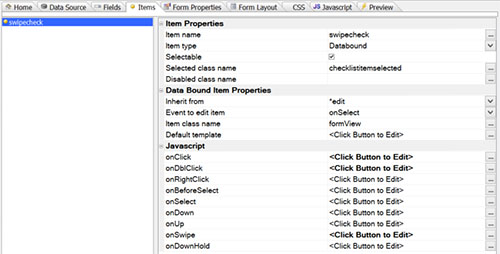 Definition of custom item type, including access to JavaScript defining behavior when tapped, double-tapped, and swiped
Alpha Anywhere has already had features that are needed for tablet form use, such as support for text, numbers, image, and GPS data. It already has robust support for off-line operation, so important for use outside of an office in the field, factory, clinic, and warehouse. We have recently added better support for video, audio, and image data, including automatic local storage with deferred uploading and downloading to and from Amazon S3 or corporate storage. There is now resampling of audio and images as needed to better match the needs of storage and data transmission, trimming the high sample rates and pixel counts produced by the tablet sensors as appropriate to the task.
As you can see in the sample application, we have added digital "ink" as a data-type. This includes a powerful, configurable writing environment on the tablet, with zooming and editing modes on par with popular standalone native tablet apps, as well as support on the server for incorporating the ink data into reports. Annotations may be over captured images or simulated paper. Additional annotation methods are also in development.
The ability to use separate editors instead of in-place editing on a form opens up many ways to best make use of touch user interfaces. In-place editing is still possible with or without a separate editor, as the sample app shows with check-list items that can be swiped for in-place changes or tapped for separate editing. Those editors may be automatically created by Alpha Anywhere for common cases, or they may be customized using the same low-code rapid application development functionality as the rest of Alpha Anywhere.
Summary
Data capture is not new. The use of paper forms, entered into a computer, is just one step along the way. Paper forms gave us a limited, constrained view of the real world that we are measuring. The capabilities of tablets and the availability of huge, inexpensive, quickly accessed data stores, help us break out of the shackles of the legacy of punched cards. Data capture has a big mixture of repetition and customization. For developing Tablet-Optimized Forms, a development system needs to allow for easy repeating of field attributes, along with easy customization of the visual presentation and layout, and the type of input controls.
-Dan Bricklin, August 18, 2015
|
|
|
© Copyright 1999-2018 by Daniel Bricklin
All Rights Reserved.
|